Reference
A recommended setup consists in:
- 2 Hues and 1 Load Balancer
- Databases: MySQL InnoDB, PostgreSQL, Oracle
- Authentication: LDAP or Username/Password
Typical setups range from 2 to 5 Hue servers, e.g. 3 Hue servers, 300+ unique users, peaks at 125 users/hour with 300 queries
In practice ~50 users / Hue peak time is the rule of thumb. This is accounting for the worse case scenarios and it will go much higher with the upcoming Task Server and Gunicorn integrations. Most of the scale issues are actually related to resource intensive operations like large download of query results or when an RPC call from Hue to a service is slow (e.g. submitting a query hangs when Hive is slow), not by the number of users.
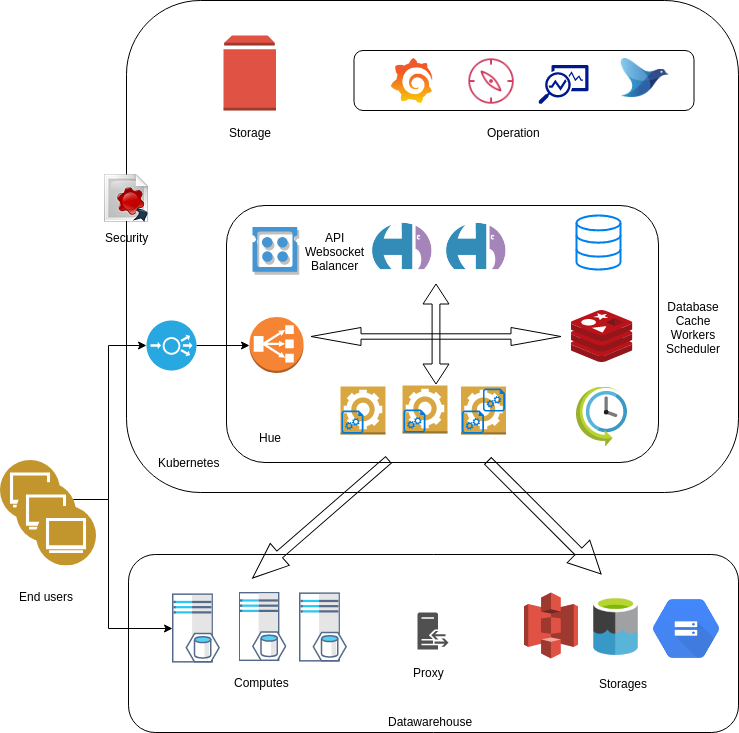
Performance
General
-
Hue must be behind a load balancer proxying static files. e.g. NGINX is used for the containers, Cloudera Hue ships with HTTPD.
-
Adding more Hue instances behind the load balancer will increase performances by 50 concurrent users.
-
Database backend should be such as MySql/Postgres/Oracle. Hue does not work on SQLite as it makes concurrent write calls to the database.
-
Check the number of documents in the Hue database. If they are too many (more than 100 000), delete the old records: Stop the Hue service. Log on to the host of your Hue server. Go to Hue directory and run following clean up command:
cd /opt/cloudera/parcels/CDH/lib/hue # Hue home directory ./build/env/bin/hue desktop_document_cleanup
-
There are some memory fragmentation issues in Python that manifest in Hue. Check the memory usage of Hue periodically. Browsing HDFS dir with many files, downloading a query result, copying a HDFS files are costly operations memory wise.
The Config Check page of Hue (/hue/about/) in the administrator section will warn about detected risks. Make sure it is at zero.
Hue comes with caching of SQL metadata throughout all the application, meaning the list of tables or a database or the column description of a table are only fetched once and re-used in the autocomplete, table browser, left and right panels etc.. The profiling of calls adds in the logs with a total time taken by each request automatically logged.
e.g.
[24/Jul/2019 14:17:32 +0000] resource DEBUG GET /jobs Got response in 151ms: {"total":0,"offset":1,"len":1,"coordinatorjobs":[]}
[24/Jul/2019 14:17:32 +0000] access INFO 127.0.0.1 romain - "POST /jobbrowser/api/jobs HTTP/1.1" returned in 157ms (mem: 164mb)
Query Editor
- Compare performance of the Hive Query Editor in Hue with the exact same query in a beeline shell against the exact same HiveServer2 instance that Hue is pointing to. This will determine if Hue needs to be investigated or HiveServer2 needs to be investigated.
- Check the logging configuration for HiveServer2 by going to Hive service Configuration in Cloudera Manager. Search for HiveServer2 Logging Threshold and make sure that it is not set to DEBUG or TRACE. If it is, drop the logging level to INFO at a minimum.
- Configure individual dedicated HiveServer2 instances for each Hue instance separate from HiveServer2 instances used by other 3rd party tools or clients, or configure Hue to point to multiple HS2 instances behind a Load Balancer.
- Tune the query timeouts for HiveServer2 (in hive-site.xml) and Impala on the hue_safety_valve or hue.ini: Query Life Cycle Downloading queries past a few thousands rows will lag and increase CPU/memory usage in Hue by a lot. It is for this we are truncating the results until further improvements.
Load Balancers
Hue is often run with:
- Cherrypy with NGINX (recommended)
- Cherrypy with HTTPD (built-in when using Cloudera Manager) (recommended)
- Gunicorn
- Apache mod Python
Queries life cycle
But what happens to the query results? How long are they kept? Why do they disappear sometimes? Why are some Impala queries are still “in flight” even if they are completed? Each query is using some resources in Impala or HiveServer2. When the users submit a lot of queries, they are going to add up and crash the servers if nothing is done. Here are the latest settings that you can tweak:
Impala
Hue tries to close the query when the user navigates away from the result page (as queries are generally fast, it is ok to close them quick). However, if the user never comes back checking the result of the query or never close the page, the query is going to stay. Impala is going to automatically expire the queries idle for than 10 minutes with the query_timeout_s property.
[impala]
# If > 0, the query will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that query within QUERY_TIMEOUT_S seconds.
query_timeout_s=600
# If > 0, the session will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that session within QUERY_TIMEOUT_S seconds (default 1 hour).
session_timeout_s=3600
Until this version, the only alternative workaround to close all the queries, is to restart Hue (or Impala).
Note: Impala currently only cancels the query but does not close it. It will be improved in a future version with IMPALA-1575. In the meantime specify a -idle_session_timeout=20 in the Impala flags (“Command Line Argument Advanced Configuration Snippet (Safety Valve)”). This setting is also available in the Hue configuration.
Hive
Hue never closes the Hive queries by default (as some queries can take hours of processing time). Also if your query volume is low (e.g. < a few hundreds a day) and you restart HiveServer2 every week, you are probably not affected. To get the same behavior as Impala (and close the query when the user leaves the page), switch on in the hue.ini:
[beeswax]
# Hue will try to close the Hive query when the user leaves the editor page.
# This will free all the query resources in HiveServer2, but also make its results inaccessible.
close_queries=true
Some close_query and close_session commands were added:
build/env/bin/hue close_queries --help
Usage: build/env/bin/hue close_queries [options] <age_in_days> (default is 7)
Closes the non running queries older than 7 days. If <all> is specified, close the ones of any types.
To run, be sure to export these environment variables:
export HUE_CONF_DIR="/var/run/cloudera-scm-agent/process/`ls -alrt /var/run/cloudera-scm-agent/process | grep HUE | tail -1 | awk '{print $9}'`"
export HIVE_CONF_DIR="/var/run/cloudera-scm-agent/process/`ls -alrt /var/run/cloudera-scm-agent/process | grep HUE | tail -1 | awk '{print $9}'`/hive-conf"
Then for example:
./build/env/bin/hue close_queries 0
Closing (all=False) HiveServer2 queries older than 0 days...
1 queries closed.
./build/env/bin/hue close_sessions 0 hive
Closing (all=False) HiveServer2 sessions older than 0 days...
1 sessions closed.
You can then add this commands into a crontab and expire the queries older than N days.
Like Impala, HiveServer2 can now automatically expires queries. So tweak hive-site.xml with:
<property>
<name>hive.server2.session.check.interval</name>
<value>3000</value>
<description>The check interval for session/operation timeout, which can be disabled by setting to zero or negative value.</description>
</property>
<property>
<name>hive.server2.idle.session.timeout</name>
<value>3000</value>
<description>Session will be closed when it's not accessed for this duration, which can be disabled by setting to zero or negative value.</description>
</property>
<property>
<name>hive.server2.idle.operation.timeout</name>
<value>0</value>
<description>Operation will be closed when it's not accessed for this duration of time, which can be disabled by setting to zero value. With positive value, it's checked for operations in terminal state only (FINISHED, CANCELED, CLOSED, ERROR). With negative value, it's checked for all of the operations regardless of state</description>
</property>
Note
This is the recommended solution for Hive. User wishing to keep some result for longer can issue a CREATE TABLE AS SELECT … or export the results in Hue.
Impala and Hive HA
How to optimally configure your Analytic Database for High Availability with Hue and other SQL clients.
HiveServer2 and Impala support High Availability through a “load balancer”. One caveat is that Hue's underlying Thrift libraries reuse TCP connections in a pool, a single user session may not have the same Impala or Hive TCP connection. If a TCP connection is balanced away from the previously selected HiveServer2 or Impalad instance, the user session and its queries can be lost and trigger the “Results have expired” or “Invalid session Id” errors.
To prevent sessions from being lost, we need configure the load balancer with “source” algorithm to ensure each Hue instance sends all traffic to a single HiveServer2/Impalad instance. Yes, this is not true load balancing, but a configuration for failover High Availability. HiveSever2 or Impala coordinators already distribute the work across the cluster so this is not an issue.
To enable an optimal load distribution that works for everybody, we can create multiple profiles in our load balancer, per port for Hue clients and non-Hue clients like Hive or Impala. We can configure non-Hue clients to distribute loads with “roundrobin” or “leastconn” and configure Hue clients with “source” (source IP Persistence) on dedicated ports, for example, 10015 for Hive beeline commands, 10016 for Hue, 21051 for Hue-Impala interactions while 25003 for Impala shell.
As shown in above diagram, you can configure the HaProxy to have two different ports associated with different load balancing algorithms. Here is a sample configuration (haproxy.cfg) for Hive and Impala HA on a secure cluster.
#-----------------------
# main frontend which proxys to the backends
#-----------------------
frontend hiveserver2_front
bind *:10015 ssl crt /path/to/cert_key.pem
mode tcp
option tcplog
default_backend hiveserver2
#-----------------------
# round robin balancing between the various backends
#-----------------------
# This is the setup for HS2. beeline client connect to load_balancer_host:load_balancer_port.
# HAProxy will balance connections among the list of servers listed below.
backend hiveserver2
balance roundrobin
mode tcp
server hiveserver2_1 host-2.com:10000 ssl ca-file /path/to/truststore.pem check
server hiveserver2_2 host-3.com:10000 ssl ca-file /path/to/truststore.pem check
server hiveserver2_3 host-1.com:10000 ssl ca-file /path/to/truststore.pem check
# Setup for Hue or other JDBC-enabled applications.
# In particular, Hue requires sticky sessions.
# The application connects to load_balancer_host:10016, and HAProxy balances
# connections to the associated hosts, where Hive listens for JDBC requests on port 10015.
#-----------------------
# main frontend which proxys to the backends
#-----------------------
frontend hivejdbc_front
bind *:10016 ssl crt /path/to/cert_key.pem
mode tcp
option tcplog
stick match src
stick-table type ip size 200k expire 30m
default_backend hivejdbc
#-----------------------
# source balancing between the various backends
#-----------------------
# HAProxy will balance connections among the list of servers listed below.
backend hivejdbc
balance source
mode tcp
server hiveserver2_1 host-2.com:10000 ssl ca-file /path/to/truststore.pem check
server hiveserver2_2 host-3.com:10000 ssl ca-file /path/to/truststore.pem check
server hiveserver2_3 host-1.com:10000 ssl ca-file /path/to/truststore.pem check
# The list of Impalad is listening at port 21000 for beeswax (impala-shell) or original ODBC driver.
# For JDBC or ODBC version 2.x driver, use port 21050 instead of 21000.
#-----------------------
# main frontend which proxys to the backends
#-----------------------
frontend impala_front
bind *:25003 ssl crt /path/to/cert_key.pem
mode tcp
option tcplog
default_backend impala
#-----------------------
# round robin balancing between the various backends
#-----------------------
backend impala
balance leastconn
mode tcp
server impalad1 host-3.com:21000 ssl ca-file /path/to/truststore.pem check
server impalad2 host-2.com:21000 ssl ca-file /path/to/truststore.pem check
server impalad3 host-4.com:21000 ssl ca-file /path/to/truststore.pem check
# Setup for Hue or other JDBC-enabled applications.
# In particular, Hue requires sticky sessions.
# The application connects to load_balancer_host:21051, and HAProxy balances
# connections to the associated hosts, where Impala listens for JDBC requests on port 21050.
#-----------------------
# main frontend which proxys to the backends
#-----------------------
frontend impalajdbc_front
bind *:21051 ssl crt /path/to/cert_key.pem
mode tcp
option tcplog
stick match src
stick-table type ip size 200k expire 30m
default_backend impalajdbc
#-----------------------
# source balancing between the various backends
#-----------------------
# HAProxy will balance connections among the list of servers listed below.
backend impalajdbc
balance source
mode tcp
server impalad1 host-3.com:21050 ssl ca-file /path/to/truststore.pem check
server impalad2 host-2.com:21050 ssl ca-file /path/to/truststore.pem check
server impalad3 host-4.com:21050 ssl ca-file /path/to/truststore.pem check
service haproxy restart
service haproxy status
[impala]
server_port=21051
[beeswax]
hive_server_port=10016
Monitoring
Performing a GET /desktop/debug/is_alive will return a 200 response if running.
Behind a Proxy
A Web proxy lets you centralize all the access to a certain URL and prettify the address e.g.
ec2-54-247-321-151.compute-1.amazonaws.com --> demo.gethue.com
Here is one way to do it with NGINX or Apache.
Task Server
Beta Feature
The task server is currently a work in progress to outsource all the blocking or resource intensive operations outside of the API server. Follow #1526 for more information on when first usable task will be released.
Until then, here is how to try the task server service.
Make sure you have Redis installed and running.
sudo apt-get install redis-server -y
In hue.ini, telling the API server that the Task Server is available:
[desktop]
[[task_server]]
enabled=true
Starting the Task server:
./build/env/bin/celery worker -l info -A desktop
Tasks
Query Task
When the task server is enabled, SQL queries are going to be submitted outside of the Hue servers.
To configure the storage to use to persist those, edit the result_file_storage setting:
[desktop]
[[task_server]]
result_file_storage='{"backend": "django.core.files.storage.FileSystemStorage", "properties": {"location": "/var/lib/hue/query-results"}}'
Email Task
Task Scheduler
For schedules configured statically in Python:
./build/env/bin/celery -A desktop beat -l info
For schedules configured dynamically via a table with Django Celery Beat:
[desktop]
[[task_server]]
beat_enabled=true
Then:
./build/env/bin/celery -A desktop beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler
Note: the first time the tables need to be created with:
./build/env/bin/hue migrate
Flower
Web UI to monitor tasks:
./build/env/bin/pip install flower
./build/env/bin/celery flower --broker=redis://localhost:6379/0
Then open-up http://localhost:5555/tasks