Connectors
Configuration
Config file
Hue connects to any database or warehouse via native Thrift or SqlAlchemy connectors that need to be added to the Hue ini file. Except [impala] and [beeswax] which have a dedicated section, all the other ones should be appended below the [[interpreters]] of [notebook] e.g.:
[notebook]
[[interpreters]]
[[[mysql]]]
name=MySQL
interface=sqlalchemy
options='{"url": "mysql://user:password@localhost:3306/hue"}'
[[[presto]]]
name = Presto
interface=sqlalchemy
options='{"url": "presto://localhost:8080/hive/default"}'
Note that USER and PASSWORD can be prompted to the user by using variables like mysql://${USER}:${PASSWORD}@localhost:3306/hue.
Most of the interpreters require to install their SqlAlchemy dialect (e.g. ./build/env/bin/pip install pyhive) either in the global Python environment or in the Hue virtual environment.
Read about how to build your own parser if you are looking at better autocompletes for your the SQL dialects you use.
Connectors
Admins can configure the connectors via the UI or API. This feature requires the Hue 5 feature flag set and is quite functional despite not being officially released and on by default.
[desktop]
enable_connectors=true
enable_hue_5=true
NOTE: After enabling the above flags, if a django.db.utils.OperationalError: (1054, "Unknown column 'useradmin_huepermission.connector_id' in 'field list'") error comes, then try changing the DB name in the hue.ini under [[database]] because there is no upgrade path and run the migrate command ./build/env/bin/hue migrate.
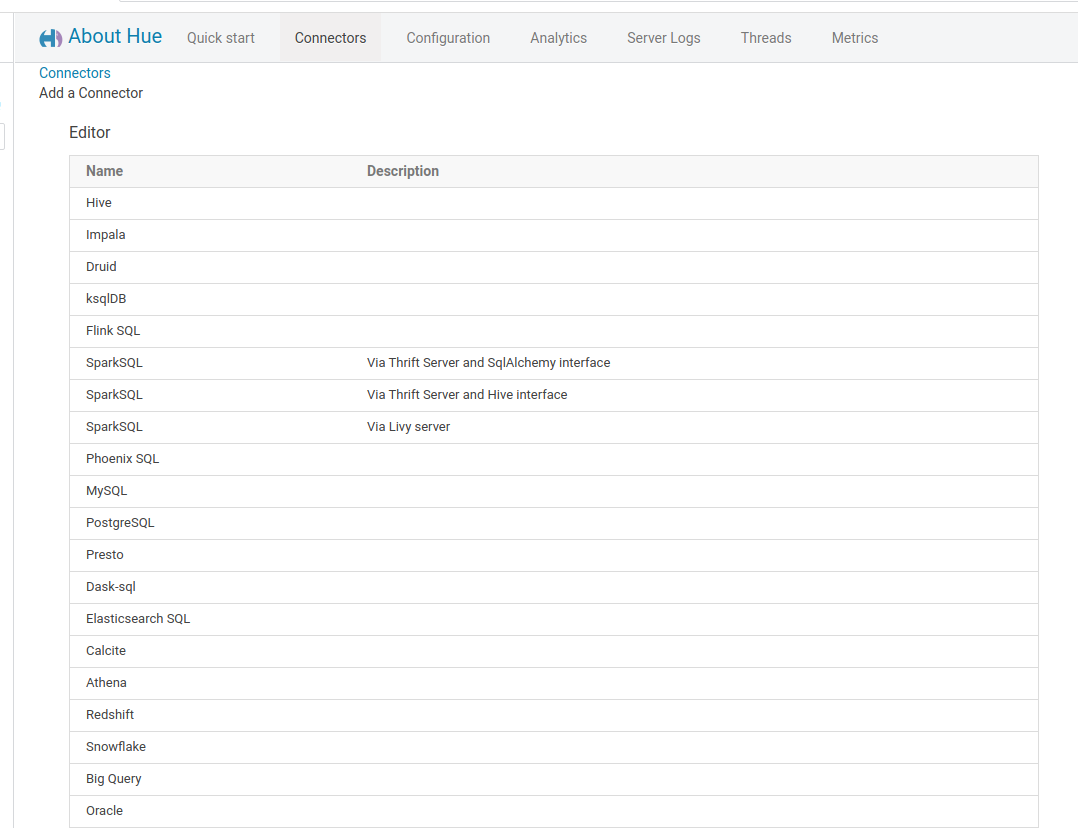
Go to Administer Server > Connectors > + Connector or directly navigate to the page http://127.0.0.1:8000/hue/desktop/connectors.
Connectors are also configurable via the public REST API.
Databases
Here is the list of dialects:
Apache Hive
The Dev Onboarding documentation demoes the integration.
Support is native via a dedicated section.
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=localhost
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
Read more about LDAP or PAM pass-through authentication and High Availability.
Note For historical reason, the name of the configuration section is [beeswax].
Tez
Requires support for sending multiple queries when using Tez (instead of a maximum of just one at the time). You can turn it on with this setting:
[beeswax]
max_number_of_sessions=3
LLAP
When the LLAP interpreter is added, there are 2 ways to enable connectivity (direct configuration or service discovery). LLAP is added by enabling the following settings:
[notebook]
[[interpreters]]
[[[llap]]]
name=LLAP
interface=hiveserver2
[beeswax]
# Direct Configuration
llap_server_host = localhost
llap_server_port = 10500
llap_server_thrift_port = 10501
# or Service Discovery
## hive_discovery_llap = true
## hive_discovery_llap_ha = false
# Shortcuts to finding LLAP znode Key
# Non-HA - hiveserver-interactive-site - hive.server2.zookeeper.namespace ex hive2 = /hive2
# HA-NonKerberized - <llap_app_name>_llap ex app name llap0 = /llap0_llap
# HA-Kerberized - <llap_app_name>_llap-sasl ex app name llap0 = /llap0_llap-sasl
## hive_discovery_llap_znode = /hiveserver2-hive2
Service Discovery
When setup, Hue will query zookeeper to find an enabled hiveserver2 or LLAP endpoint.
[beeswax]
hive_discovery_llap = true
hive_discovery_hs2 = true
In order to prevent spamming zookeeper, HiveServer2 is cached for the life of the process and llap is cached based on the following setting:
[beeswax]
cache_timeout = 60
HPL/SQL
It is an Apache open source procedural extension for SQL for Hive users. This HPL/SQL Editor post demoes the integration.
[[[hplsql]]]
name=Hplsql
interface=hiveserver2
Note:
- HPL/SQL uses the
[beeswax]config like Hive uses. - In hplsql mode, you must terminate the commands using the forward slash character (/). The semicolon (;) is used throughout procedure declarations and can no longer be relied upon to terminate a query in the editor.
Apache Impala
This Impala SQL Editor post demoes the integration.
Support is native via a dedicated section.
[impala]
# Host of the Impala Server (one of the Impalad)
server_host=localhost
# Port of the Impala Server
server_port=21050
Read more about LDAP or PAM pass-through authentication and High Availability.
MySQL
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install mysqlclient
Then give Hue the information about the database source:
[[[mysql]]]
name=MySQL
interface=sqlalchemy
options='{"url": "mysql://root:root@localhost:3306/hue"}'
## mysql://${USER}:${PASSWORD}@localhost:3306/hue
Query string options are documented in the SqlAlchemy MySQL documentation.
Alternative:
[[[mysqljdbc]]]
name=MySql JDBC
interface=jdbc
## Specific options for connecting to the server.
## The JDBC connectors, e.g. mysql.jar, need to be in the CLASSPATH environment variable.
## If 'user' and 'password' are omitted, they will be prompted in the UI.
options='{"url": "jdbc:mysql://localhost:3306/hue", "driver": "com.mysql.jdbc.Driver", "user": "root", "password": "root"}'
## options='{"url": "jdbc:mysql://localhost:3306/hue", "driver": "com.mysql.jdbc.Driver"}'
Presto
Presto has been forked into Trino and both share the same configuration.
Currently just substitute ‘presto’ with ‘trino’ or vice versa.
Trino
To support Trino in Hue, we're leveraging the official Trino Python client
Install at least the 0.329.0 version of trino from https://github.com/trinodb/trino-python-client or https://pypi.org/project/trino/
./build/env/bin/pip install trino
Then give Hue the information about the trino cluster:
[[[trino]]]
name=Trino
interface=trino
options='{"url": "http://localhost:8080"}'
With credentials:
options='{"url": "http://localhost:8080", "auth_username": "", "auth_password":""}'
With password script:
options='{"url": "http://localhost:8080", "auth_username": "", "auth_password_script":""}'
Note Currently, only basic LDAP authentication using username and password or password script is supported. Alternatively, you can establish unsecured Trino connections.
Oracle
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install cx_Oracle
Then give Hue the information about the database source:
[[[oracle]]]
name = Oracle
interface=sqlalchemy
options='{"url": "oracle://user:password@localhost"}'
PostgreSQL
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install psycopg2
or
./build/env/bin/pip install psycopg2-binary
Then give Hue the information about the database source:
[[[postgresql]]]
name = PostgreSql
interface=sqlalchemy
options='{"url": "postgresql+psycopg2://user:password@localhost:31335/database"}'
AWS Athena
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install PyAthena
Then give Hue the information about the database source:
[[[athena]]]
name = AWS Athena
interface=sqlalchemy
options='{"url": "awsathena+rest://${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}@athena.${REGION}.amazonaws.com:443/${SCHEMA}?s3_staging_dir=${S3_BUCKET_DIRECTORY}&work_group=${WORK_GROUP}&catalog_name=${CATALOG_NAME}"}'
e.g.
options='{"url": "awsathena+rest://XXXXXXXXXXXXXXXXXXXX:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX@athena.us-west-2.amazonaws.com:443/default?s3_staging_dir=s3://gethue-athena/scratch&work_group=demo_group&catalog_name=AwsDataCatalog"}'
Note: Keys and S3 buckets need to be URL quoted but Hue does it automatically for you.
Apache Phoenix
This Phoenix SQL Editor post demoes the integration.
The official Phoenix dialect is already shipped in Hue. However if you want to update it yourself:
./build/env/bin/pip install phoenixdb
Then give Hue the information about the database source:
[[[phoenix]]]
name=HBase Phoenix
interface=sqlalchemy
options='{"url": "phoenix://sql-phoenix.gethue.com:8765/"}'
If using security:
[[[phoenix]]]
name=HBase Phoenix
interface=sqlalchemy
options='{"url": "phoenix://sql-phoenix.gethue.com:8765", "tls": true, "connect_args": {"authentication": "SPNEGO", "verify": false }}'
Grant the appropriate hbase rights to the ‘hue’ user, e.g.:
grant 'hue', 'RWXCA'
With impersonation:
options='{"url": "phoenix://sql-phoenix.gethue.com:8765", "has_impersonation": true}'
Notes
-
Existing HBase tables need to be mapped to views
0: jdbc:phoenix:> CREATE VIEW if not exists "analytics_demo_view" ( pk VARCHAR PRIMARY KEY, "hours"."01-Total" VARCHAR ); Error: ERROR 505 (42000): Table is read only. (state=42000,code=505) --> 0: jdbc:phoenix:> CREATE Table if not exists "analytics_demo" ( pk VARCHAR PRIMARY KEY, "hours"."01-Total" VARCHAR ); -
Tables are seeing as uppercase by Phoenix. When getting started, it is simpler to just create the table via Phoenix.
Error: ERROR 1012 (42M03): Table undefined. tableName=ANALYTICS_DEMO (state=42M03,code=1012) --> 0: jdbc:phoenix:> select * from "analytics_demo" where pk = "domain.0" limit 5; -
Phoenix follows Apache Calcite. Feel free to help improve the SQL autocomplete support for it.
-
The UI (and the underlying SQLAlchemy API) cannot distinguish between ‘ANY namespace’ and ‘empty/Default’ namespace
Apache Druid
This Druid SQL Editor post demoes the integration.
First, make sure that Hue can talk to Druid via the pydruid SqlAlchemy connector.
./build/env/bin/pip install pydruid
In the hue.ini configuration file, now let's add the interpreter. Here ‘druid-host.com’ would be the machine where Druid is running.
[notebook]
[[interpreters]]
[[[druid]]]
name = Druid
interface=sqlalchemy
options='{"url": "druid://druid-host.com:8082/druid/v2/sql/?header=true"}'
?header=true option requires Druid 13.0 or later.
Adding the +https prefix will use HTTPS e.g.:
druid+https://druid-host.com:8082/druid/v2/sql/?header=true
Apache Flink
This Flink Stream SQL Editor post demoes the integration.
The dialect currently requires the Flink SQL Gateway in order to submit queries.
Then add a Flink interpreter in the Hue configuration:
[notebook]
[[interpreters]]
[[[flink]]]
name=Flink
interface=flink
options='{"url": "http://172.18.0.7:8083"}'
ksqlDB
This ksqlDB Stream SQL Editor post demoes the integration.
The ksql Python module should be added to the system or Hue Python virtual environment:
./build/env/bin/pip install ksql
Note The connector requires Hue with Python 3
Then give Hue the information about the interpreter and ksqlDB server. To add to the list of interpreters:
[[[ksqlDB]]]
name=ksqlDB
interface=ksql
options='{"url": "http://ksqldb-server:8088"}'
Google BigQuery
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install pybigquery
./build/env/bin/pip install pyasn1==0.4.1
From https://github.com/mxmzdlv/pybigquery.
Then give Hue the information about the database source:
[[[bigquery]]]
name = BigQuery
interface=sqlalchemy
options='{"url": "bigquery://project-XXXXXX", "credentials_json": "{\"type\": \"service_account\", ...}"}'
Where to get the Json credentials? By creating a service account:
- https://googleapis.dev/python/google-api-core/latest/auth.html
- https://console.cloud.google.com/iam-admin/serviceaccounts
Where to get the names? In the ‘Resources’ panel of Big Query UI:
- Project name, e.g. project-XXXXXX, bigquery-public-data…, is the first level
- Dataset name, e.g. austin_bikeshare, is the second level
To restrict to one dataset:
options='{"url": "bigquery://project-XXXXXX/dataset_name"}'
Supporting additional connection parameters:
options='{"url": "bigquery://", "use_query_cache": "true"}'
Materialize
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install psycopg2
or
./build/env/bin/pip install psycopg2-binary
Then give Hue the information about the database source:
[[[postgresql]]]
name = Materialize
interface=sqlalchemy
options='{"url": "postgresql://user:password@localhost:6875/"}'
Teradata
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-teradata
Then give Hue the information about the database source:
[[[teradata]]]
name = Teradata
interface=sqlalchemy
options='{"url": "teradata://user:password@localhost"}'
Alternative:
[[[teradata]]]
name=Teradata JDBC
interface=jdbc
options='{"url": "jdbc:teradata://sqoop-teradata-1400.sjc.cloudera.com/sqoop", "driver": "com.teradata.jdbc.TeraDriver", "user": "sqoop", "password": "sqoop"}'
DB2
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install ibm_db_sa
(or via https://github.com/ibmdb/python-ibmdbsa/tree/master/ibm_db_sa)
Then give Hue the information about the database source:
[[[db2]]]
name = DB2
interface=sqlalchemy
options='{"url": "db2+ibm_db://user:password@hostname[:port]/database"}'
Alternative:
[[[db2]]]
name=DB2 JDBC
interface=jdbc
options='{"url": "jdbc:db2://db2.vpc.cloudera.com:50000/SQOOP", "driver": "com.ibm.db2.jcc.DB2Driver", "user": "DB2INST1", "password": "cloudera"}'
Apache Spark SQL
This Spark SQL Editor post demoes the integration.
There are two ways to connect depending on your infrastructure:
Distributed SQL Engine
Hue supports two interfaces: SqlAlchemy and native Thrift. Native Thrift should support better long running queries better, but might have some nits here and there.
SqlAlchemy
With SqlAlchemy the dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install git+https://github.com/gethue/PyHive
Note: SqlAlchemy interface requires the Hive connector which does not work out of the box because of the issue #150. But Hue ships and show a slightly patched module that works.
This module might also be needed:
./build/env/bin/pip install thrift_sasl
Then give Hue the information about the database source:
[[[sparksql]]]
name=Spark SQL
interface=sqlalchemy
options='{"url": "hive://user:password@localhost:10000/database"}'
Distributed SQL Engine / Thrift Server
With the HiveServer Thrift (same as the one used by Hive and Impala so more robust depending on the use cases):
[spark]
# Host of the Spark Thrift Server
# https://spark.apache.org/docs/latest/sql-distributed-sql-engine.html
sql_server_host=localhost
# Port of the Spark Thrift Server
sql_server_port=10000
And make sure you have a sparksql interpreter configured:
[[[sparksql]]]
name=Spark SQL
interface=hiveserver2
Apache Livy
Apache Livy provides a bridge to a running Spark interpreter so that SQL, pyspark and Scala snippets can be executed interactively.
This Spark SQL Editor with Livy post demoes the integration.
[spark]
# The Livy Server URL.
livy_server_url=http://localhost:8998
And as always, make sure you have an interpreter configured:
[[[sparksql]]]
name=Spark SQL
interface=livy
Azure SQL Database
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install pyodbc
Then configure ODBC according to the documentation.
Then give Hue the information about the database source:
[[[azuresql]]]
name = Azure SQL Server
interface=sqlalchemy
options='{"url": "mssql+pyodbc://<user>@<server-host>:<password>@<server-host>.database.windows.net:1433/<database>?driver=ODBC+Driver+13+for+SQL+Server"}'
Note: Properties need to be URL quoted (e.g. with urllib.quote_plus(...) in Python).
Read more on the Azure SQL Database.
MS SQL Server
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install pymssql
Then give Hue the information about the database source:
[[[mssql]]]
name = SQL Server
interface=sqlalchemy
options='{"url": "mssql+pymssql://<username>:<password>@<freetds_name>/?charset=utf8"}'
Alternative:
Microsoft’s SQL Server JDBC drivers can be downloaded from the official site: Microsoft JDBC Driver
[[[sqlserver]]]
name=SQLServer JDBC
interface=jdbc
options='{"url": "jdbc:microsoft:sqlserver://localhost:1433", "driver": "com.microsoft.jdbc.sqlserver.SQLServerDriver", "user": "admin": "password": "pass"}'
Vertica
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-vertica-python
Then give Hue the information about the database source:
[[[vertica]]]
name = Vertica
interface=sqlalchemy
options='{"url": "vertica+vertica_python://user:pwd@localhost:port/database"}'
Alternative:
Be sure to download the Vertica’s JDBC client driver for the right version and OS.
[[[vertica]]]
name=Vertica JDBC
interface=jdbc
options='{"url": "jdbc:vertica://localhost:5433/example", "driver": "com.vertica.jdbc.Driver", "user": "admin", "password": "pass"}'
AWS Redshift
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-redshift
Then give Hue the information about the database source:
[[[redshift]]]
name = Redshift
interface=sqlalchemy
options='{"url": "redshift+psycopg2://[email protected]:5439/database"}'
Apache Drill
The dialect is available on https://github.com/JohnOmernik/sqlalchemy-drill
Then give Hue the information about the database source:
[[[drill]]]
name = Drill
interface=sqlalchemy
options='{"url": "drill+sadrill://..."}'
## To use Drill with SQLAlchemy you will need to craft a connection string in the format below:
# drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
## To connect to Drill running on a local machine running in embedded mode you can use the following connection string.
# drill+sadrill://localhost:8047/dfs?use_ssl=False
Alternative:
The Drill JDBC driver can be used.
[[[drill]]]
name=Drill JDBC
interface=jdbc
## Specific options for connecting to the server.
## The JDBC connectors, e.g. mysql.jar, need to be in the CLASSPATH environment variable.
## If 'user' and 'password' are omitted, they will be prompted in the UI.
options='{"url": "<drill-jdbc-url>", "driver": "org.apache.drill.jdbc.Driver", "user": "admin", "password": "admin"}'</code>
SAP Sybase
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install python-sybase
Then give Hue the information about the database source:
[[[sybase]]]
name = Sybase
interface=sqlalchemy
options='{"url": "sybase+pysybase://<username>:<password>@<dsn>/[database name]"}'
SAP Hana
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-hana
(or via https://github.com/SAP/sqlalchemy-hana)
Then give Hue the information about the database source:
[[[db2]]]
name = DB2
interface=sqlalchemy
options='{"url": "hana://username:[email protected]:30015"}'
Apache Solr
SQL
Query Solr collections like you would query a regular database via Solr SQL.
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-solr
(or via https://github.com/aadel/sqlalchemy-solr)
Then give Hue the information about the database source:
[[[solr]]]
name = Solr SQL
interface=sqlalchemy
options='{"url": "solr://<username>:<password>@<host>:<port>/solr/<collection>[?use_ssl=true|false]"}'
Note
There is also a native implementation which has some caveats (HUE-3686 but reuses the Dashboard configuration which is builtin in CDH/CDP.
First make sure Solr is configured for Dashboards (cf. section just below):
Then add the interpreter:
[[[solr]]]
name = Solr SQL
interface=solr
## Name of the collection handler
# options='{"collection": "default"}'
Dashboards
Hue ships the dynamic dashboardsfor exploring datasets visually. Just point to an existing Solr server:
[search]
# URL of the Solr Server
solr_url=http://localhost:8983/solr/
# Requires FQDN in solr_url if enabled
## security_enabled=false
## Query sent when no term is entered
## empty_query=*:*
Apache Kylin
Apache Kylin is an open-source online analytical processing (OLAP) engine. See how to configure the Kylin Query Editor.
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install kylinpy
Then give Hue the information about the database source:
[[[kylin]]]
name = Kylin
interface=sqlalchemy
options='{"url": "kylin://..."}'
Alternative:
[[[kylin]]]
name=kylin JDBC
interface=jdbc
options='{"url": "jdbc:kylin://172.17.0.2:7070/learn_kylin", "driver": "org.apache.kylin.jdbc.Driver", "user": "ADMIN", "password": "KYLIN"}'
Dask SQL
dask-sql adds a SQL layer on top of Dask. It uses the Presto wire protocol for communication, so the SqlAlchemy dialect for Presto should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install pyhive
Then give Hue the information about the database source:
[[[dasksql]]]
name=Dask SQL
interface=sqlalchemy
options='{"url": "presto://localhost:8080/catalog/default"}'
Clickhouse
The qlalchemy-clickhouse dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install sqlalchemy-clickhouse
Then give Hue the information about the database source:
[[[clickhouse]]]
name = Clickhouse
interface=sqlalchemy
# e.g. clickhouse://user:[email protected]:8124/test?protocol=https
options='{"url": "clickhouse://localhost:8123"}'
Note:
If facing an error like:
ModuleNotFoundError: No module named 'connector'
Update:
./build/env/bin/pip install pytz==2021.1
Alternative:
[[[clickhouse]]]
name=ClickHouse
interface=jdbc
## Specific options for connecting to the ClickHouse server.
## The JDBC driver clickhouse-jdbc.jar and its related jars need to be in the CLASSPATH environment variable.
options='{"url": "jdbc:clickhouse://localhost:8123", "driver": "ru.yandex.clickhouse.ClickHouseDriver", "user": "readonly", "password": ""}'
Apache Kyuubi
Apache Kyuubi is a distributed and multi-tenant gateway to provide serverless SQL on data warehouses and lakehouses.
Give Hue the information about the database source:
[[[kyuubi]]]
name=Kyuubi
interface=jdbc
## Specific options for connecting to the Kyuubi server.
## The JDBC driver kyuubi-hive-jdbc-shaded.jar and its related jars need to be in the CLASSPATH environment variable.
options='{"url": "jdbc:hive2://localhost:10009", "driver": "org.apache.kyuubi.jdbc.KyuubiHiveDriver", "user": "readonly", "password": ""}'
Elastic Search
The dialect for https://github.com/elastic/elasticsearch should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install elasticsearch-dbapi
Then give Hue the information about the database source:
[[[es]]]
name = Elastic Search
interface=sqlalchemy
options='{"url": "elasticsearch+http://localhost:9200/"}'
Apache Pinot DB
The dialect for https://pinot.apache.org should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install pinotdb
Then give Hue the information about the database source:
[[[pinot]]]
name = Pinot
interface=sqlalchemy
options='{"url": "pinot+http://localhost:8099/query?server=http://localhost:9000/"}'
Snowflake
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install snowflake-sqlalchemy
Then give Hue the information about the database source:
[[[snowflake]]]
name = Snowflake
interface=sqlalchemy
options='{"url": "snowflake://{user}:{password}@{account}/{database}"}'
Note: account is the name in your URL domain. e.g.
https://smXXXXXX.snowflakecomputing.com/ --> smXXXXXX
Tables currently need to be prefixed with a schema, e.g. SELECT * FROM tpch_sf1.customer LIMIT 5
e.g.
options='{"url": "snowflake://hue:pwd@smXXXXX/SNOWFLAKE_SAMPLE_DATA"}'
Read more about is on the snowflake-sqlalchemy page.
Sqlite
Just give Hue the information about the database source:
[[[sqlite]]]
name = Sqlite
interface=sqlalchemy
options='{"url": "sqlite:///path/to/database.db"}'
Google Sheets
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install gsheetsdb
Then give Hue the information about the database source:
[[[GSheets]]]
name = Google Sheets
interface=sqlalchemy
options='{"url": "gsheets://"}'
Read more on the gsheetsdb page.
Greenplum
The dialect should be added to the Python system or Hue Python virtual environment:
./build/env/bin/pip install psycopg2
Then give Hue the information about the database source:
[[[greenplum]]]
name = Greenplum
interface=sqlalchemy
options='{"url": "postgresql+psycopg2://user:password@localhost:31335/database"}'
Storage
HDFS
Hue supports one HDFS cluster. That cluster should be defined under the [[[default]]] sub-section.
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://hdfs-name-node.com:8020
webhdfs_url=http://hdfs-name-node.com:20101/webhdfs/v1
HA is supported by pointing to the HttpFs service instead of the NameNode.
Make sure the HDFS service has in it hdfs-site.xml:
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
Configure Hue as a proxy user for all other users and groups, meaning it may submit a request on behalf of any other user:
WebHDFS: Add to core-site.xml:
<!-- Hue WebHDFS proxy user setting -->
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
HttpFS: Verify that /etc/hadoop-httpfs/conf/httpfs-site.xml has the following configuration:
<!-- Hue HttpFS proxy user setting -->
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
If the configuration is not present, add it to /etc/hadoop-httpfs/conf/httpfs-site.xml and restart the HttpFS daemon. Verify that core-site.xml has the following configuration:
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
If the configuration is not present, add it to /etc/hadoop/conf/core-site.xml and restart Hadoop.
Apache Ozone
Hue can read and write files on the Ozone filesystem, similar to HDFS. Add the following settings under [desktop], and within the [[ozone]] section:
[[[default]]]
fs_defaultfs=ofs://[***SERVICE-ID***]
webhdfs_url=http://[***OZONE-HTTPFS-HOST***]:[***OZONE-HTTPFS-PORT***]/webhdfs/v1
ssl_cert_ca_verify=true
security_enabled=true
Where,
- fs_defaultfs: Ozone service ID (HA mode) or URL for Ozone Manager (non-HA mode).
- webhdfs_url: URL of HttpFS endpoint for the running Ozone service (
httpsfor secure service elsehttp).
Configure Hue as a proxy user for all other users and groups, meaning it may submit a request on behalf of any other user:
HttpFS: Verify or add the following configuration in Ozone service's httpfs-site.xml:
<!-- Hue HttpFS proxy user setting -->
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
S3
Hue's filebrowser can now allow users to explore, manage, and upload data in an S3 account, in addition to HDFS and Ozone.
Read more about it in the S3 User Documentation.
In order to add an S3 account to Hue, you'll need to configure Hue with valid S3 credentials, including the access key ID and secret access key.
These keys can securely stored in a script that outputs the actual access key and secret key to stdout to be read by Hue (this is similar to how Hue reads password scripts). In order to use script files, add the following section to your hue.ini configuration file:
[aws]
[[aws_accounts]]
[[[default]]]
access_key_id_script=/path/to/access_key_script
secret_access_key_script= /path/to/secret_key_script
allow_environment_credentials=false
region=us-east-1
Alternatively (but not recommended for production or secure environments), you can set the access_key_id and secret_access_key values to the plain-text values of your keys:
[aws]
[[aws_accounts]]
[[[default]]]
access_key_id=s3accesskeyid
secret_access_key=s3secretaccesskey
allow_environment_credentials=false
region=us-east-1
The region should be set to the AWS region corresponding to the S3 account. By default, this region will be set to ‘us-east-1’.
Using Ceph New end points have been added in HUE-5420
Azure File Systems
Hue's file browser can now allow users to explore, manage, and upload data in an ADLS v1 or ADLS v2 (ABFS), in addition to HDFS, Ozone and S3.
In order to add an Azure account to Hue, you'll need to configure Hue with valid Azure credentials, including the client ID, client secret and tenant ID. These keys can securely stored in a script that outputs the actual access key and secret key to stdout to be read by Hue (this is similar to how Hue reads password scripts). In order to use script files, add the following section to your hue.ini configuration file:
[azure]
[[azure_account]]
[[[default]]]
client_id=adlsclientid
client_secret=adlsclientsecret
tenant_id=adlstenantid
The account name used by ADLS / ABFS will need to be configured via the following properties:
[[adls_clusters]]
[[[default]]]
fs_defaultfs=adl://<account_name>.azuredatalakestore.net
webhdfs_url=https://<account_name>.azuredatalakestore.net
[[abfs_clusters]]
[[[default]]]
fs_defaultfs=abfs://<container_name>@<account_name>.dfs.core.windows.net
webhdfs_url=https://<container_name>@<account_name>.dfs.core.windows.net
GCS
Hue's file browser for Google Cloud Storage is currently a work in progress with HUE-8978
The json credentials of a service account can be stored for development in plain-text
[desktop]
[[gc_accounts]]
[[[default]]]
json_credentials='{ "type": "service_account", "project_id": .... }'
HBase
Specify the comma-separated list of HBase Thrift servers for clusters in the format of “(name|host:port)":
[hbase]
hbase_clusters=(Cluster|localhost:9090)
Impersonation
doAs Impersonation provides a flexible way to use the same client to impersonate multiple principals. doAs is supported only in Thrift 1. Enable doAs support by adding the following properties to hbase-site.xml on each Thrift gateway:
<property>
<name>hbase.regionserver.thrift.http</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>true</value>
</property>
And the Hue hosts, or * to authorize from any host:
<property>
<name>hadoop.proxyuser.hbase.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.groups</name>
<value>*</value>
</property>
Note: If you use framed transport, you cannot use doAs impersonation, because SASL does not work with Thrift framed transport.
Kerberos cluster
In a secure cluster its also needs these properties:
<property>
<name>hbase.thrift.spnego.principal</name>
<value>HTTP/<hostname_from_above>@REALM</value>
<!-->Note, _HOST does not work. ## Can be found from CM-Administration->Security->Kerberos Credentials (HTTP/....)</!-->
</property>
<property>
<name>hbase.thrift.spnego.keytab.file</name>
<value>hbase.keytab/value>
</property>
And from the HBase shell, authorize some ends users, e.g. to give full access to admin:
hbase shell> grant 'admin', 'RWXCA'
Metadata
Apache Atlas
In the [metadata] section, Hue is supporting Cloudera Navigator and Apache Atlas in order to enrich the data catalog.
[metadata]
[[catalog]]
# The type of Catalog: Apache Atlas, Cloudera Navigator...
interface=atlas
# Catalog API URL (without version suffix).
api_url=http://localhost:21000/atlas/v2
# Username of the CM user used for authentication.
## server_user=hue
# Password of the user used for authentication.
server_password=
# Limits found entities to a specific cluster. When empty the entities from all clusters will be included in the search results.
## search_cluster=
# Set to true when authenticating via kerberos instead of username/password
## kerberos_enabled=false
Cloudera Navigator
The integration was replaced with Apache Atlas but can still be used.
Cloudera Navigator Optimizer
The integration is powering the Risk Alerts and Popular Values in the SQL Autocomplete.
Jobs
Apache Spark
This connector leverage the Apache Livy REST Api.
In the [[interpreters]] section:
[[[pyspark]]]
name=PySpark
interface=livy
[[[sparksql]]]
name=SparkSql
interface=livy
[[[spark]]]
name=Scala
interface=livy
[[[r]]]
name=R
interface=livy
In the [spark] section:
[spark]
# The Livy Server URL.
livy_server_url=http://localhost:8998
And if using Cloudera distribution, make sure you have notebooks enabled:
[desktop]
app_blacklist=
[notebook]
show_notebooks=true
YARN: Spark session could not be created
If seeing an error similar to this with primitiveMkdir:
The Spark session could not be created in the cluster: at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy10.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2333) ... 20 more
19/05/13 12:27:07 INFO util.ShutdownHookManager: Shutdown hook called 19/05/13 12:27:07 INFO util.ShutdownHookManager:
Deleting directory /tmp/spark-0d045154-77a0-4e12-94b2-2df18725a4ae YARN Diagnostics:
Does your logged-in user have a home dir on HDFS (i.e. /user/bob)? (you should see the full error in the Livy or YARN logs).
In Hue admin for you user, you can click the ‘Create home’ checkbox and save.
CSRF
Livy supports a configuration parameter in the Livy conf:
livy.server.csrf-protection.enabled
…which is false by default. Upon trying to launch a Livy session from the notebook, Hue will pass along the connection error from Livy as a 400 response that the “Missing Required Header for CSRF protection”. To enable it, add to the Hue config:
[spark]
# Whether Livy requires client to use csrf protection.
## csrf_enabled=false
Impersonation
Let’s say we want to create a shell running as the user bob, this is particularly useful when multi users are sharing a Notebook server
curl -X POST --data '{"kind": "pyspark", "proxyUser": "bob"}' -H "Content-Type: application/json" localhost:8998/sessions
{"id":0,"state":"starting","kind":"pyspark","proxyUser":"bob","log":[]}
Do not forget to add the user running Hue (your current login in dev or hue in production) in the Hadoop proxy user list (/etc/hadoop/conf/core-site.xml):
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
Apache Pig
Pig is native to Hue and depends on the Oozie service to be configured:
[[[pig]]]
name=Pig
interface=oozie
Apache Oozie
In oder to schedule workflows, the [liboozie] section of the configuration file:
[liboozie]
oozie_url=http://oozie-server.com:11000/oozie
Make sure that the Share Lib is installed.
To configure Hue as a default proxy user, add the following properties to /etc/oozie/conf/oozie-site.xml:
<!-- Default proxyuser configuration for Hue -->
<property>
<name>oozie.service.ProxyUserService.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>oozie.service.ProxyUserService.proxyuser.hue.groups</name>
<value>*</value>
</property>
Apache YARN
Hue supports one or two Yarn clusters (two for HA). These clusters should be defined
under the [[[default]]] and [[[ha]]] sub-sections.
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]]
[[[default]]]
resourcemanager_host=yarn-rm.com
resourcemanager_api_url=http://yarn-rm.com:8088/
proxy_api_url=http://yarn-proxy.com:8088/
resourcemanager_port=8032
history_server_api_url=http://yarn-rhs-com:19888/
Apache Sentry
To have Hue point to a Sentry service and another host, modify these hue.ini properties:
[libsentry]
# Hostname or IP of server.
hostname=localhost
# Port the sentry service is running on.
port=8038
# Sentry configuration directory, where sentry-site.xml is located.
sentry_conf_dir=/etc/sentry/conf
Hue will also automatically pick up the server name of HiveServer2 from the sentry-site.xml file of /etc/hive/conf.
{kind=link}
And that’s it, you can know specify who can see/do what directly in a Web UI! The app sits on top of the standard Sentry API and so it fully compatible with Sentry. Next planned features will bring Solr Collections, HBase privilege management as well as more bulk operations and a tighter integration with HDFS.
To be able to edit roles and privileges in Hue, the logged-in Hue user needs to belong to a group in Hue that is also an admin group in Sentry (whatever UserGroupMapping Sentry is using, the corresponding groups must exist in Hue or need to be entered manually). For example, our ‘hive’ user belongs to a ‘hive’ group in Hue and also to a ‘hive’ group in Sentry:
<property>
<name>sentry.service.admin.group</name>
<value>hive,impala,hue</value>
</property>
Notes
- Create a role in the Sentry app through Hue
- Grant privileges to that role such that the role can see the database in the Sentry app
- Create a group in Hue with the same name as the role in Sentry
- Grant that role to a user in Hue
- Ensure that the user in Hue has an equivalent O/S level
- Ensure a user has an O/S level account on all hosts and that user is part of a group with the same name as the group in Hue (this assumes that the default ShellBasedUnixGroupsMapping is set for HDFS in CM)
Our users are:
- hive (admin) belongs to the hive group
- user1_1 belongs to the user_group1 group
- user2_1 belongs to the user_group2 group
We synced the Unix users/groups into Hue with these commands:
export HUE_CONF_DIR="/var/run/cloudera-scm-agent/process/`ls -alrt /var/run/cloudera-scm-agent/process | grep HUE | tail -1 | awk '{print $9}'`"
build/env/bin/hue useradmin_sync_with_unix --min-uid=1000
If using the package version and has the CDH repository register, install sentry with:
sudo apt-get install sentry
If using Kerberos, make sure ‘hue’ is allowed to connect to Sentry in /etc/sentry/conf/sentry-site.xml:
<property>
<name>sentry.service.allow.connect</name>
<value>impala,hive,solr,hue</value>
</property>
Here is an example of sentry-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>sentry.service.security.mode</name>
<value>none</value>
</property>
<property>
<name>sentry.service.admin.group</name>
<value>hive,romain</value>
</property>
<property>
<name>sentry.service.allow.connect</name>
<value>impala,hive,solr</value>
</property>
<property>
<name>sentry.store.jdbc.url</name>
<value>jdbc:derby:;databaseName=sentry_store_db;create=true</value>
</property>
<property>
<name>sentry.store.jdbc.driver</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>sentry.store.jdbc.password</name>
<value>aaa</value>
</property>
</configuration>
Apache Knox
[[knox]]
# This is a list of hosts that knox proxy requests can come from
## knox_proxyhosts=server1.domain.com,server2.domain.com
# List of Kerberos principal name which is allowed to impersonate others
## knox_principal=knox1,knox2
# Comma separated list of strings representing the ports that the Hue server can trust as knox port.
## knox_ports=80,8443